導入の背景
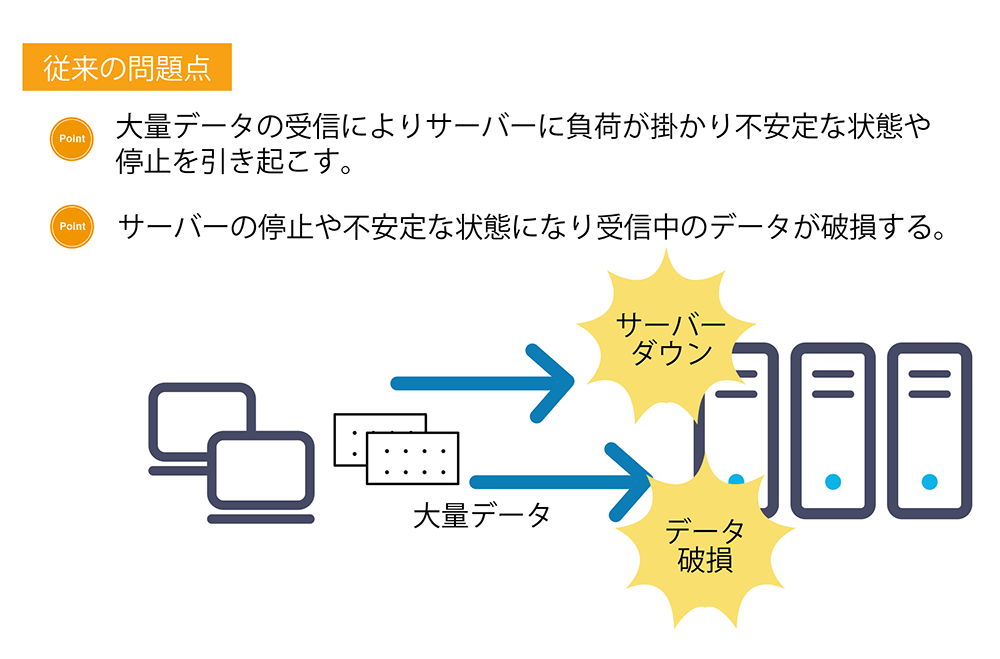
データストリーミングやIoTセンサーの技術導入が進む中でデータ処理時に発生する大規模データを効率良く処理する仕組みが近年注目されています。
またインターネット通信の高速化に伴い大規模データの集計や処理を、より速くに完了させるスピード感が求められています。
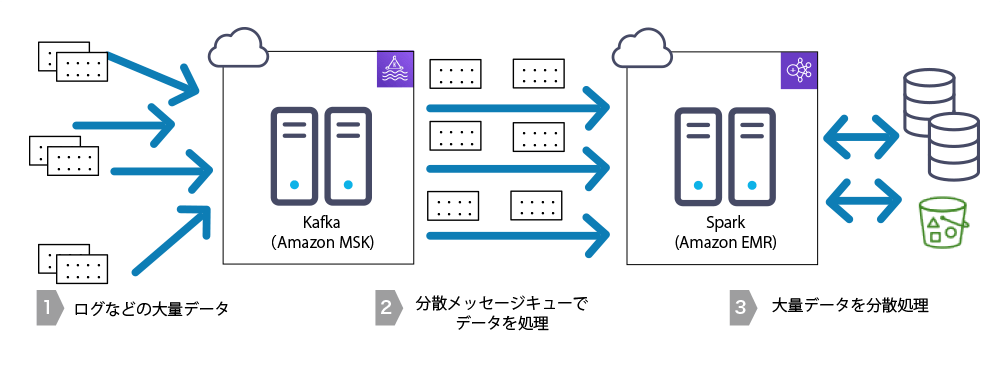
当社もこのような大規模データを高速で行う分散処理技術を取り入れた開発・ケーススタディを取り組んで参りました。特にサーバーレスに特化したAmazon Web Service(AWS)を用いた開発を得意としており、AWSが提供するAmazon MSK(Amazon Managed Streaming for Apache Kafka)、Amazon EMRの技術を積極的に取り入れています。
これらの技術は、従来は主にトランザクションの多い金融系、動画ストリーミング、IoTセンサーなどで利用されてきましたが 様々な業種への導入が容易となってきています。
Amazon MSKの特徴
(Amazon Managed Streaming for Apache Kafka)
Apache Kafkaは大規模なストリームデータを扱うことが出来るオープンソースの分散処理システムです。このApache Kafkaは管理しずらいなどの欠点がありますが、Amazon MSKではApache Kafkaをストリーミング処理する為のアプリケーションの実行や管理を自動で行なってくれます。
1.拡張性が高い
ブローカーやストレージの拡張性が高く、必要に応じて規模を換えることができます。
2.多くのストリーム処理エンジンやツールがKafkaに対応
Apache Kafka APIに対応して構築された既存のオープンソースツールをサポートしている為、アプリケーションのコードを修正せずに既存のApache KafkaアプリケーションがAmazon MSKクラスターを操作できるようになります。
3.暗号化とセキュリティ
特殊なツールや設定を行わなくても転送時や保管時にデータを暗号化することができます。
Amazon EMRの特徴
(Amazon Elastic MapReduce)
大量データを処理するApache Spark、Hadoopなどのビッグデータフレームワークの構築や運用、また分散アプリケーションの実行を行います。
1.伸縮自在
オンプレミスのクラスターのような伸縮性の低いインフラストラクチャと異なりコンピューティングとストレージが分離されているため、
使用料に応じてクラスターのサイズを自由に加減することができます。
使用料に応じてクラスターのサイズを自由に加減することができます。
2.使いやすさ
統合開発環境 (IDE) である EMR Studio を使うことで、チームで共同作業を行いながら、データの処理、探索、そして可視化などを進めることが可能となります。
また使用するコンピューティングとアプリケーションを選択するだけであとの設定、調整はEMRが行います。
また使用するコンピューティングとアプリケーションを選択するだけであとの設定、調整はEMRが行います。
3.安全性
ユーザーが管理する又はAWS Key Management Serviceが管理するキーを使用することで、クライアント側の暗号化、サーバー側の暗号化の実行が可能となります。
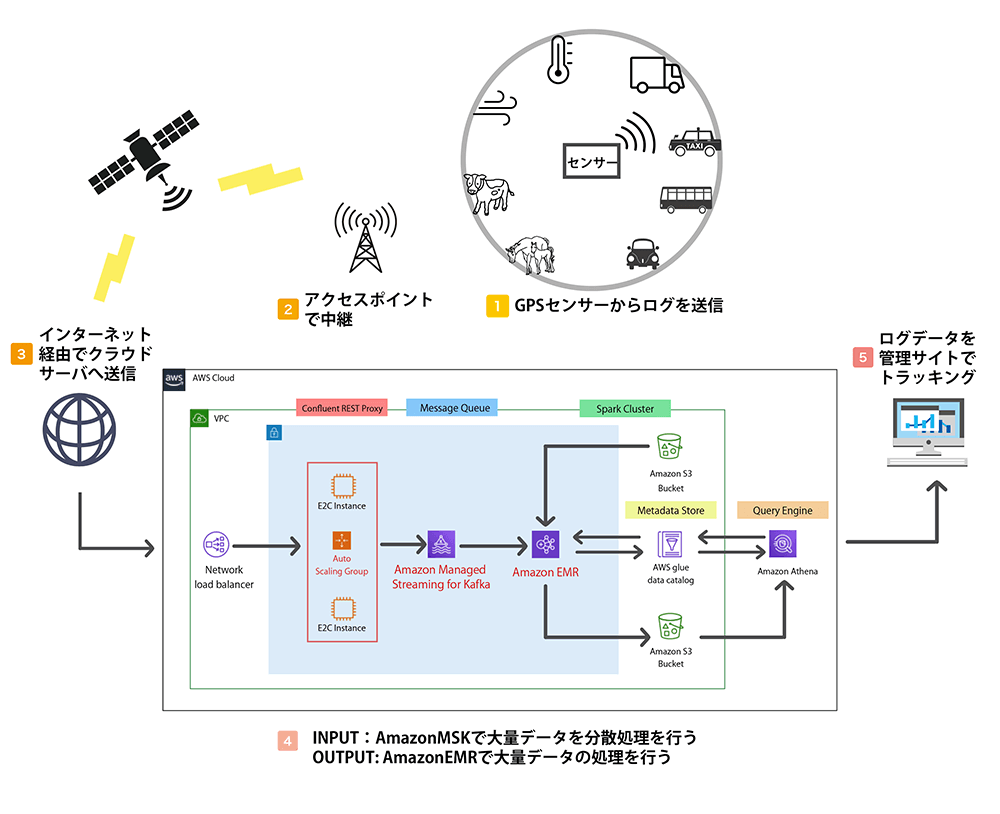
導入事例
| ケース | センサーログの大量データ処理 |
| 対象業種 | 配送業(デリバリー、宅配便、運送など)、牧場、農業、水族館、動物園 他 |
| 機能 | 対象物に取り付けられたGPSセンサー、温度センサーなどから送られてくる大量のログデータをAmazon MSKで受信しそのデータをAmazon EMRで適所な処理を実行しデータの保管、分析等を行う。 |
IAJにお任せください
- お客様のご希望、環境に合った開発プランをご提案いたします。
- IAJでは経験豊富な技術者がお客様が不安とされている技術面でサポートいたします。
- CI/CDを導入して開発、テスト、運用まで効率良い開発プランをご提案いたします。